

Is de maat ertoe?
Geheugenvereisten zijn het meest voor de hand liggende voordeel van het verminderen van de complexiteit van de interne gewichten van een model. Het Bitnet B1.58-model kan worden uitgevoerd met slechts 0,4 GB geheugen, vergeleken met overal van 2 tot 5 GB voor andere open-gewichtsmodellen van ongeveer dezelfde parametergrootte.
Maar het vereenvoudigde wegingssysteem leidt ook tot een efficiëntere werking bij inferentietijd, met interne bewerkingen die veel meer afhankelijk zijn van eenvoudige toevoegingsinstructies en minder op computationeel dure vermenigvuldigingsinstructies. Die efficiëntieverbeteringen betekenen dat Bitnet B1.58 overal van 85 tot 96 procent minder energie gebruikt in vergelijking met vergelijkbare modellen met volledige precisie, schatten de onderzoekers.
Een demo van Bitnet B1.58 met snelheid op een Apple M2 CPU.
Door een zeer geoptimaliseerde kernel te gebruiken die speciaal is ontworpen voor de Bitnet-architectuur, kan het Bitnet B1.58-model ook meerdere keren sneller worden uitgevoerd dan vergelijkbare modellen die op een standaard volledig-precisie-transformator worden uitgevoerd. Het systeem is efficiënt genoeg om “snelheden te bereiken vergelijkbaar met menselijke lezing (5-7 tokens per seconde)” met behulp van een enkele CPU, de onderzoekers schrijven (je kunt die geoptimaliseerde kernels zelf downloaden en uitvoeren op een aantal arm en x86 CPU’s, of probeer het met deze webdemo).
Cruciaal is dat de onderzoekers zeggen dat deze verbeteringen niet ten koste gaan van prestaties op verschillende benchmarks die redeneren, wiskunde en “kennis” -mogelijkheden testen (hoewel die claim nog niet onafhankelijk moet worden geverifieerd). Gemiddeld de resultaten op verschillende gemeenschappelijke benchmarks, ontdekten de onderzoekers dat Bitnet “mogelijkheden bijna op gelijke voet bereikt met toonaangevende modellen in zijn grootteklasse en tegelijkertijd een dramatisch verbeterde efficiëntie biedt.”
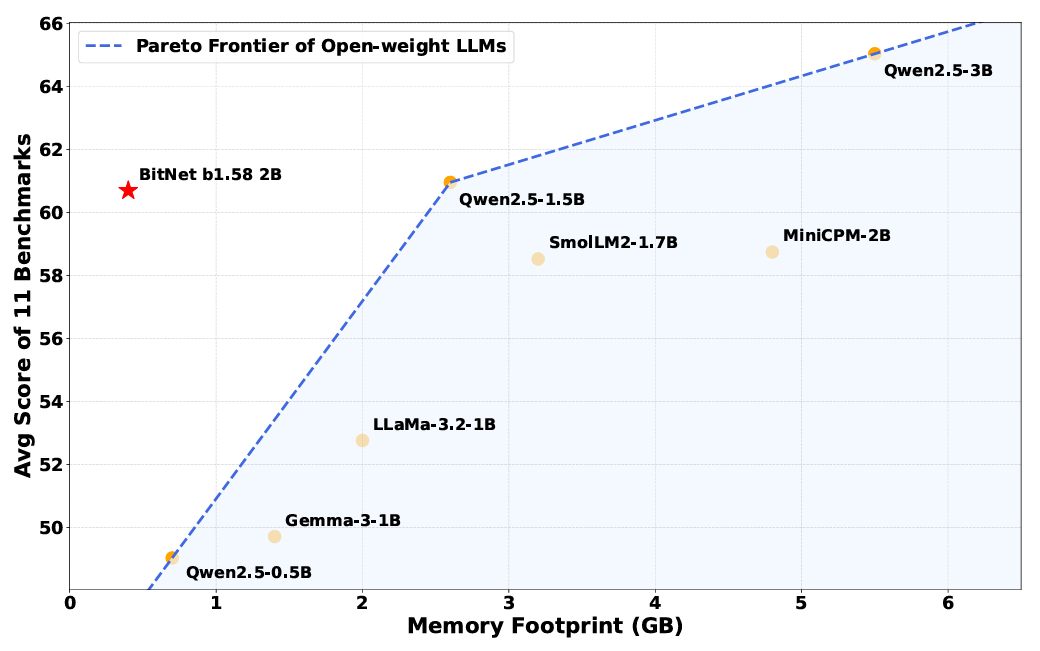
Ondanks zijn kleinere geheugenvoetafdruk presteert Bitnet nog steeds op dezelfde manier als “volledige precisie” gewogen modellen op veel benchmarks.
Ondanks zijn kleinere geheugenvoetafdruk presteert Bitnet nog steeds op dezelfde manier als “volledige precisie” gewogen modellen op veel benchmarks.
Ondanks het schijnbare succes van dit bitnetmodel “Proof of Concept”, schrijven de onderzoekers dat ze niet helemaal begrijpen waarom het model werkt als met zo’n vereenvoudigde weging. “Dieper ingaan op de theoretische onderbouwing van waarom 1-bits training op schaal effectief is, blijft een open gebied”, schrijven ze. En er is nog steeds meer onderzoek nodig om deze bitnetmodellen te laten concurreren met de algehele grootte en contextvenster “geheugen” van de grootste modellen van vandaag.
Toch toont dit nieuwe onderzoek een potentiële alternatieve aanpak voor AI -modellen die worden geconfronteerd met spiraalvormige hardware- en energiekosten van het uitvoeren van dure en krachtige GPU’s. Het is mogelijk dat de “volledige precisie” -modellen van vandaag zijn als spierauto’s die veel energie en moeite verspillen wanneer het equivalent van een mooi subcompact vergelijkbare resultaten zou kunnen opleveren.

: Modern en Tasty, met voorbehouden")

{kind=link}